



Working on software projects has always meant dealing with uncertainty about delivery times. The industry has evolved in how it approaches the need for upfront information about time and costs in software development. We eventually learned (or tolerated) to live with short-lived forecasts about developer team output, given that waterfall-style processes lacked the accuracy needed to ensure successful projects.
Today, we’re facing a new era where AI models are unleashing unprecedented software capabilities. The software we’re building now can interact with users using natural language, execute tasks with novel levels of autonomy, and make decisions that aren’t programmed with traditional deterministic code expressing business logic.
As usual with new technological advances, we’re adapting and learning to better estimate the time and effort required to build software. However, when features rely more on LLM integrations rather than deterministic code alone, we face new uncertainties.
The first question stakeholders will likely ask is WHAT can be achieved with AI in our products, rather than WHEN it will be implemented. The WHAT question takes different forms: How accurate will my AI-powered agent be? How well will the AI chat assistant we want to build perform? Remember, this technology comes with the ubiquitous disclaimer: “the model can make mistakes—you must verify important information.”
AI-powered features carry a degree of uncertainty similar to what we’ve always faced with delivery times. We now have capability uncertainty.
We’ve been improving over time at estimating what frontier models can achieve in different use cases. But this is a race against the rapid progress made in the field of generative models. And it is almost impossible to catch up with all the models variants and providers available.
We can handle this new uncertainty by organizing work in short iterations with frequent planning, adapting as we learn. We rely on quick experimentation cycles to reduce risks and form a realistic picture of what our AI-powered solutions can achieve.
The following is our default process for tackling these challenges every time we discuss an AI-based feature or system with a client.
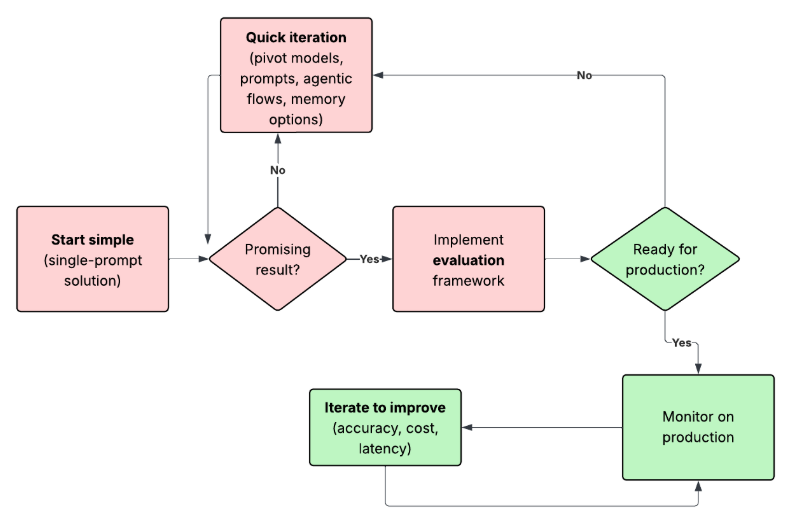
The red steps represent the most experimental part, where the highest levels of uncertainty and risk lie. We want to navigate these phases as quickly and effectively as possible, always moving toward gaining critical knowledge that will form the foundation supporting the project’s future if feasibility is confirmed.
We’re constantly exploring better ways to move faster in initial experiments. This involves prototyping extensively using AI development tools and the most appropriate frameworks available. In particular, implementing an evaluation framework in early stages is proving crucial to learning faster—though we need to carefully invest the right time and effort on this, again using an iterative approach.
We do all of this because when working with LLMs, quality is non-deterministic, improvements are non-linear (tiny changes can dramatically improve or tank results), and you often don’t know what’s possible until you explore.
The table below compares the two types of uncertainty we encounter in AI software projects.
| Dimension | Traditional Software | AI-Powered Features |
|---|---|---|
| Primary Uncertainty | Schedule Uncertainty | Capability Uncertainty |
| Question | “When will it be ready?” | “Can it achieve the required quality?” |
| Approach | Plan → Build → Ship | Probe → Evaluate → Iterate |
| Definition of Done | Clear upfront | Emerges through testing & evals |
| Risk | Delay | Low or inconsistent capability |
Ultimately, we want to ensure the software we create delivers real value to users and clients.
We’ve heard the buzz about high AI projects failure rates and know this isn’t easy. At the same time, we’re excited about what can be created by incorporating more AI into the products we build—so let’s work together to create the shiny new experiences our users will love.